
Fugatto is a framework for audio synthesis and transformation given text instructions and optional audio inputs. The framework includes the generative model Fugatto, a dataset creation technique that exploits relationships between audio and text, and a method for controlling and composing instructions, including from different models, called ComposeableART.
We envision Fugatto as a tool for creatives, empowering them to quickly bring their sonic fantasies and unheard sounds to life—an instrument for imagination, not a replacement for creativity.
Creative Examples
This section provides a collection of sound pieces that were created by first using Fugatto to create and modify assets, then using a digital audio workstation to combine them.
1. Rap Song
[Singing Voice Synthesis (SVS), Text-To-Speech Synthesis (TTS), Text-To-Audio Synthesis (TTA)]
| Fugatto | Audio Context |
|---|---|
2. Introduction for a Movie and Recitativo Accompagnato
[Singing Voice Synthesis (SVS), Text-To-Speech Synthesis (TTS), Text-To-Audio Synthesis (TTA)]
| Fugatto |
|---|
Emergent Sounds
[Text-To-Audio Synthesis (TTA)]
This section provides a collection of sound snippets that are unlikely to exist in the real world and in the training data. Assuming the text instructions describe the task, and that Fugatto has not seen such instructions during training, Fugatto is able to execute these tasks without explicit supervision.
| Fugatto | Instruction | Emergence? |
|---|---|---|
| Synthesize Electronic Dance Music, Dogs Barking, Cats Meowing. | Dogs barking in sync with the music. | |
| Synthesize Banjo and Rainfall | Unlikely existence of banjo and rain sounds at the same time in the training data. | |
| Synthesize Drum kit and ticking clock. | Clocks tick but not musically nor with the sound of drum sticks. | |
| Design factory machinery that screams in metallic agony. | Factory machinery does not scream in agony. | |
| Produce a typewriter that whispers each letter typed. | Typewriters generally have a strong onset for every letter typed. | |
| Produce a soundscape with a choir of sirens to produce a lush and calm choir composition with sustained chords. | Music instruments, not sirens, create choirs and lush chords. | |
| Produce an oral delivery of a male dog barking in English saying the words "I need to know… who let the dogs out?", with the sound of a male dog barking. | Dogs don't speak and people, normally, do not bark. | |
| Produce an oral delivery of a violin playing a beautiful solo in English saying the words "I need to know; Who let the dogs out?", sounding like a violin playing a beautiful solo. | People normally don't slide between notes, like a violin, when they speak. | |
| Synthesize a cello shouting with anger and a cello screaming. | Aside from Xenakis' music, cellos do not shout in anger nor scream. | |
| Synthesize a female voice barking. | People, normally, do not bark | |
| Synthesize a flute barking and a flute meowing. | Flutes do not bark nor meow. | |
| Synthesize a saxophone barking and a saxophone meowing. | Aside from Free Jazz, Saxophones do not bark nor meow. | |
| Synthesize a saxophone barking and a saxophone meowing. | Aside from "Interstellar Spaces", Saxophones do not bark nor meow. | |
| Violin melody and baby laugh | Violins do not laugh like babies, nor do babies sound like violins. |
[ComposableART and Text-To-Audio(TTA)]
This sections provides a collection of emergent sounds achieved with our proposed ComposeableART method, that enables the interpolation, in the latent space, between instructions.
| Weights/Events | Cymbals and Flute |
Accelerating, revving, vroom and Acoustic Guitar |
Speech and Water |
Acoustic Guitar and Water |
|---|---|---|---|---|
| w1=1.0 w2=0.0 |
||||
| w1=0.75 w2=0.25 |
||||
| w1=0.5 w2=0.5 |
||||
| w1=0.25 w2=0.75 |
||||
| w1=0.0 w2=1.0 |
||||
| Emergence from combination? | From cymbals to gamelan to flute. | From revving to electric guitar with distortion to acoustic guitar. | From speech to underwater speech to water. | From acoustic guitar to underwater acoustic guitar to water. |
Emergent Tasks
[Speech Prompted Singing Voice Synthesis (Audio-Transformation)]
This section provides a collection of examples to showcase Fugatto’s ability to perform speech prompted Singing Voice Synthesis, even though it was never trained on this task. A possible explanation for this emergent ability is the model’s ability to interpolate between tasks seen during trying, i.e. (TTS given a speech prompt and SVS given a textual voice description)
| Fugatto | ||||
| Audio Context |
[Melody Prompted Singing Voice Synthesis (SVS) and Text-To-Audio (TTA)]
This section provides a collection of examples to showcase Fugatto’s ability to perform SVS and TTA when prompted with a melody, even though it was never trained on this task. A possible explanation for this emergent ability is the model’s ability to interpolate between tasks seen during trying, i.e. TTA given descriptions, SVS given a textual voice description and MIDI2AUDIO.
MIDI Melody (Audio Context)
| Fugatto | Instruction |
|---|---|
| Turn this MIDI melody into a female voice, operatic scat singing style given context: | |
| Turn this MIDI melody into a female voice, rock pop singing style given context: | |
| Turn this MIDI melody into a female voice, operatic singing style with the lyrics:"Let me sing this song\nOh oh oh oh oh oh" given context: | |
| Synthesize Deep, rumbling bass pulses paired with intermittent, high-pitched digital chirps, like the sound of a massive, sentient machine waking up given context: |
[MIDI-2-Audio (Audio-Transformation)]
This section provides a collection of examples to showcase Fugatto’s ability to convert from MIDI audio to natural Audio. We emphasize that this is zero-shot behavior and emergent capability, given that Fugatto has never seen monophonic melodies during MIDI2Audio training, with the average number of stems present in training this task being 8.
| Fugatto | ||||
| Audio Context |
ComposableART (Composable Audio Representation Transformations)
ComposableART is a technique for compositonal synthesis where we extend the Classifier Free Guidance framework to support the combination of vector fields across multiple instructions, multiple mel-frame indices and multiple models.
This section provides a collection of sound pieces that were created by applying ComposableART to Fugatto model and each of them highlights one of special features brought by ComposableART:
1. Weighted Combination
[Text-To-Audio Synthesis (TTA)]
| Weighted Combination Equal Weights on Birds and Dogs | Weighted Combination Birds Emphasized | Weighted Combination Dogs Emphasized |
|---|---|---|
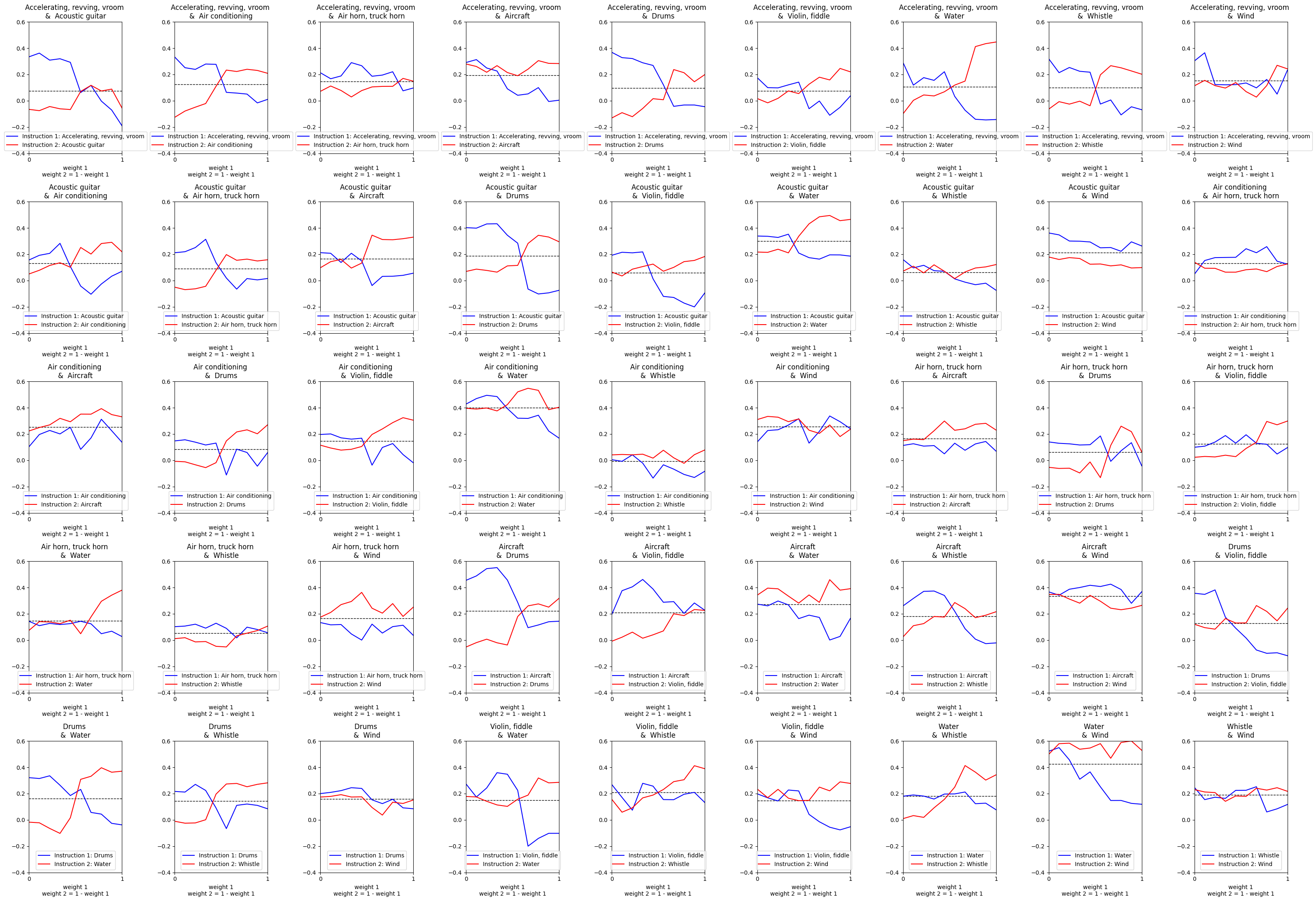
Plots with CLAP Scores for the Weighted Combination of events with ComposableART
Each plot shows the CLAP score for each instruction, or event, given the weight of that instruction.

Plots with CLAP Scores computed with a 2 second window with 1 second overlap for the Temporal Interpolation events with ComposableART
Each plot shows the CLAP score for each instruction, or event, over time
2. Negation
[Text-To-Speech (TTS)]
| Negation of 'male' with _Fugatto_ Baseline using 'Not' | Positive weight on 'male' with ComposableART | Negative weight on 'male' with ComposableART |
|---|---|---|
3. Task Composition
[Text-To-Audio Synthesis (TTA), Text-To-Speech (TTS)]
| Task Composition with audio event 'birds chirping' and music synthesis | Task Composition with audio event 'dogs barking', 'birds chirping' and music synthesis | Task Composition with audio event 'birds chirping' and text to speech(TTS) |
|---|---|---|
4. Model Composition with 2 different Fugatto models, one trained on Text-To-Audio Synthesis (TTA) and other on Text-To-Speech (TTS)
[Text-To-Audio Synthesis (TTA), Text-To-Speech (TTS)]
| Model Composition with audio event 'birds chirping' and ambient text to speech in background | Model Composition with audio event 'dogs barking' and text to speech | Model Composition with audio event 'water flowing' and text to speech |
|---|---|---|
5. Temporal Composition
[Text-To-Audio Synthesis (TTA)]
| Temporal Composition simulating a 'rainy' night transitioning into a 'chirpy' dawn. | Temporal Composition simulating 'Ukelele' melody transitioning into brass metalic 'Engine' tragedy. | Temporal Composition simulating a 'thunderous' stormy fading into a 'rainy' storm. |
|---|---|---|